Computational hysteresis in the humanities: A group-based model of new skills in science
In this chapter, we introduce a master equation model for the emergence of new skills in research groups--skills that are individually costly to learn but promoted at the group level. Our aim is to develop a flexible framework for running diverse in silico experiments and exploring the tension between individual and collective goals in research. In contrast to the previous chapter, which focused on irreducible and coupled groups, this model presents a case study of reducible and isolated groups. Examining the bimodality in our system, we find evidence of hysteresis: once groups transition into a computational regime, the system does not return to the previous state characterized by groups with few programmers. Faster transitions lead to fewer individuals leaving the system as a result of the computational shift.
Abstract
Models in the science of science are used to study the social dynamics shaping scientific practice, from the effects of parenthood on careers to invisible colleges, the Matthew effect, and other forms of epistemic inequality. While early work focused on individuals, there is growing recognition that teams---and especially research groups---play a central role in scientific development. Yet existing models often reduce teams to sets of coauthors, overlooking the latent structure and internal dynamics of research groups. We propose a master equation model to study how new skills emerge within research groups, using the spread of computer programming in the humanities as a case study. The model provides a flexible framework for running in silico experiments that examine tensions between individual and collective incentives. Programming yields increasing group-level benefits but remains individually costly to learn, especially in groups without programmers to start with. Research groups are represented as a set of disconnected hyperedges, focusing on higher-order interactions between individuals and peers.
We find that these dynamics can exhibit computational hysteresis; once a critical mass of programmer-rich groups is reached, self-reinforcing effects emerge, even as programming-poor groups persist. These transitions may produce transient yet irreversible shifts in disciplinary structure. By analyzing how cost functions shape these transitions, we offer insights for future data collection and institutional strategies to support computational adoption in the humanities.
Introduction
The history of scientific progress is also a history of craftsmanship and methods [@smith_body_2004]. Kepler is best known for deriving the laws of planetary motion, but it is not a coincidence that he was also an avid lens maker. Within disciplines, methods and tools shaped the kinds of data researchers could collect, and thus the questions they asked [@galison_image_1997; @shapin_leviathan_2011]. Today, however, disciplinary boundaries are increasingly porous: physicists do computational sociology using large-scale datasets, AI researchers won the Nobel Prize in Chemistry and Physics, and philosophers learn to program to analyze corpora. This migration is not random---methodological craft shapes which fields spill into others [@ramage_mapping_2020; @domenico_quantifying_2016]. Rapid shifts in methods can create friction between newcomers and traditionalists, eroding shared language [@brister_disciplinary_2016]. Combined with faster generational turnover---where foundational skills evolve more quickly than they are learned---this has created a new competitive dynamic; traditional training no longer reliably signals what future researchers should prioritize learning. This presents a growing challenge for students, early-career researchers, and the institutions that support them: how should they respond to a shifting methodological landscape, especially when acquiring new skills entails significant individual costs in learning environments lagging behind those competencies? How do we ensure the coexistence of tradition with that shifting landscape?
To address this question, we focus on the rise of computer programming in the humanities from a group-level perspective [@hockey_history_2004; @busa_annals_1980; @burton_automated_1981; @dignazio_data_2020]. Programming underpins many computational approaches--such as Bayesian statistics, natural language processing, or large language models--that are increasingly popular in digital humanities (see Fig. 1.1{reference-type="ref" reference="fig:riseprog"}). While these methods promise new insights that capture macroscale behaviors [@edelstein_historical_2017; @boyd-graber_applications_2017], they can also clash with humanist ideals when aligned too closely with external incentives [@gold_dh_2019]. As public funding declines, some university administrators and granting agencies increasingly emphasize "research outputs"---journal articles, books, or proceedings---to 'guide strategic decision-making' [@piper_publication_2017]. Humanities departments adopting computational tools may thus favor measurable outcomes over traditional qualitative approaches. Conversely, those resisting the urge for digital humanities might lose appeal to new generations of humanists [@heller_end_2023]. As echoed in popular news, some humanists might not care, preferring the humanities to stay true to their origins [@nakada_as_2024; @allington_neoliberal_2016]. But this becomes harder to maintain as a position when whole departments shut down, a trend observed in recent years [@taylor_university_2005; @editorial_guardian_2024; @hughes_as_2025]. From a group-level perspective, this dynamic reflects intergroup competition, wherein departments and groups are subject to selection due to differential reproduction and survival, and group-based prestige bias [@henrich_weirdest_2020].
We examine the divide between computational (programmer-rich groups) and qualitative (traditional) research as a case of potential hysteresis in public good dynamics (see Fig. 1.1{reference-type="ref" reference="fig:riseprog"}, top plot). In ecology and other fields, alternative stable state models capture how a small change has a cascading effect; going from one habitat, say a savannah, to become another one, a forest. However, reversing this shift often requires more drastic intervention, a hallmark of hysteresis [@scheffer_alternative_1993; @beisner_alternative_2003]. We apply this logic to the humanities: once a critical mass of scholars adopts computational tools, epistemic norms may "tip" in favor of programming-based methods, making a return to predominantly qualitative approaches unlikely under the same conditions. Our focus is on the transition dynamics--from an equilibrium where few possess computational expertise to one where programming is normalized. In this context, research groups must weigh the collective benefits of computational projects against the individual costs of acquiring new skills, adding a public good dimension to the hysteresis loop. We schematize one such example with history (Fig. 1.1{reference-type="ref" reference="fig:riseprog"}, bottom), where we can think of computational works invading specific epistemic communities, while others remain more qualitative.
In this paper, we shift the focus to research groups, examining how they balance individual costs and collective benefits when adopting new skills. In the context of the computational turn in the humanities, we assume individuals bear private costs to learn programming--costs that may conflict with a group's desire (or external pressure) to develop programming expertise. We define research groups as sets of shared norms and practices that hold members together, even as individuals vary in their commitment to those norms [@smaldino_cultural_2014]. By considering groups in terms of group-level features, we emphasize their capacity to coordinate learning, share knowledge, and generate feedback mechanisms that support skill development. This group-based approach moves beyond classical studies in the science of science [@wuchty_increasing_2007; @sugimoto_equity_2023; @uzzi_scientific_2012; @wang_science_2021; @lazer_computational_2009]---often focused on individual trajectories, awards, or citation metrics---and toward a more dynamic view of science as the coevolution of individual and group-level processes.
Viewing the shift toward computational methods as a social dilemma, we examine how institutions face a core trade-off in adopting emerging skills. One option is to push for a rapid transition---gaining competitive advantages through enhanced programming capacity---but at the risk of high turnover among members who struggle with new demands. This mirrors a familiar dynamic in firms adopting new technologies or selling products; whether to absorb upfront costs in the hope of long-term returns [@argote_organizational_2012]. Alternatively, research groups can adopt a more supportive approach, offering institutional resources (e.g., extended training, mentorship) to help individuals learn at a manageable pace. While this second path retains more members, it potentially delays the group's ability to compete with other, faster-moving teams. Although groups may not explicitly frame their decisions in these strategic terms, external incentives, such as funding mandates, often pressure them to accelerate adoption. This raises a core question; how can institutional practices that balance individual support with collective benefit emerge when established norms around computational skills are still developing?
In the rest of the paper, we develop a group-based model for the emergence of new skills in science and explore its potential as an effective tool for the science of science, formalizing institutional strategies to adapt to a rapidly shifting methodological landscape.
A group-based model of new skills in science
Programming uptake in the humanities reflects the joint influence of groups and individuals, that our model captures by modeling learning as a contagion process within the context of a public goods dilemma, where individuals incur private costs for group benefit. The dynamics emerges from the tension between the individuals facing a cost-benefit problem around learning to code and the group pressing individuals to learn. We first introduce the public good games (PGGs) aspect of our model, before describing the stochastic dynamics exactly through a system of master equations.
Diffusion of innovations as public goods
We consider a large population of researchers of size $N$, divided into $M$ groups of varying sizes. Researchers can either be programmers ($p$) or non-programmers ($n$). The total benefit for an individual to adopt programming is the combination of two key components; an individual-level benefit $B(x)$ and a group-level pressure $\Pi(x)$, both of which depend on the proportion of programmers in the group, $x = p/g$, where $g = n + p + 1$ is the group size (the smallest group consists of a lone principal investigator). In our baseline implementation, both functions take the same exponential form
$$B(x) = \Pi(x) = (1 - r b_\ell) e^{-x / \chi} + b_\ell$$
where $b_\ell$ denotes the baseline benefit, and $r$ controls the amplitude of the decaying exponential component. To ensure that the functions remain bounded, we impose the constraint $0 \leq r b_\ell \leq 1$. The parameter $\chi > 0$ controls how quickly the benefit declines with the fraction of programmers in the group $x = p/g$; larger values of $\chi$ correspond to slower decay, and thus more persistent benefits. It can be thought of as a benefit cutoff, that is, when $x > \chi$ the benefits of being programmers drop.
We treat $B(x)$ and $\Pi(x)$ as conceptually distinct to capture different motivations: group-level pressure to add programmers decreases with each new addition, reflecting diminishing returns. For individuals, the benefit of learning to code is highest when few or no programmers are present, making their skills more valuable. In computational groups, individuals may rely on others' expertise, reducing their incentive to learn.
While being the only programmer in a programming-poor group may be motivating, it entails higher individual costs, as captured by the logistic form
$$C(x) = (1 - r b_\ell) \frac{1}{1 + e^{k_c (x - x_c)}} + b_\ell$$
where, as with the benefit function, the cost is bounded between $b_\ell$ and $1-rb\ell$. The shape of the cost function is determined by two parameters: the steepness parameter $k_c$, which determines how sharply the cost of learning decreases as more programmers are present, and by the midpoint $x_c$, which sets the group composition at which this decrease occurs. The payoff $B(x)+\Pi(x)-C(x)$ determines the transition rate $\tau(x)$, governing how quickly non-programmers adopt programming
$$\tau(x) = \tau_0 , \frac{1}{1 + \exp\left[-k_\tau \left(B(x) + \Pi(x) - C(x)\right)\right]}$$
In sigmoid form, this encodes bounded rationality [@mcfadden_conditional_1972]; individuals are more likely to transition when the net payoff ($B(x)+\Pi(x)-C(x)$ is positive, but not guaranteed to do so. The sigmoid expresses a probability of attempting the transition with $\tau_0$ as the base rate at which the transition occurs. The parameter $k_\tau$ governs the sensitivity of the transition rate to the payoff associated with learning to code, or the agent's bounded rationality. A larger $k_\tau$ means individuals respond sharply--programming becomes appealing only when benefits clearly outweigh costs. A smaller $k_\tau$ smooths the transition, allowing adoption even with marginal net benefits. Conversely, a smaller $k_\tau$ smooths out the transition, allowing adoption even when net benefits are marginal. Overall, this treats programming as a public good: as more people learn, the cost drops for others, but each may wait, hoping others invest first.
Master equation
We combine the transition rates for learning to code with a simple population dynamics model into a set of master equations. Figure 1.2{reference-type="ref" reference="fig:schema"} graphically represents the possible transitions between group configurations
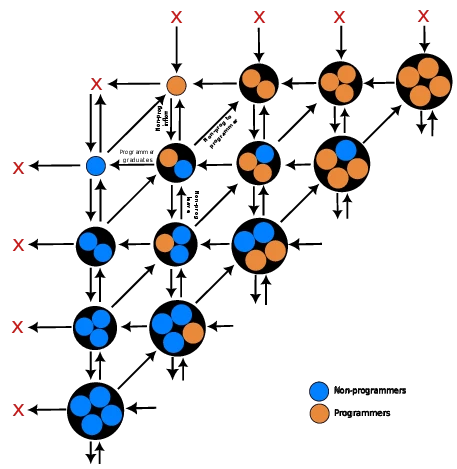
Whereas compartmental models use boxes to represent different parts of a system, here we use circles to represent the states in which a "multiverse of systems" can be found. That is, assume that we are interested in an infinite number of equivalent but independent systems in a given state. Then, we track how the probability of finding a system with group configuration $G_{n,p}$ is evolving with respect to time $t$. As such, each arrow in the schema represents a probability current flowing between adjacent group states. Since we track a probability distribution over all group configurations, the system must obey probability conservation, or detailed balanced.
Take for example our transition rate $\tau(x)$. Non-programmers attempt to learn programming at a rate $\tau$ (diagonal arrows), with a success probability $1-C(x)$. This generates probability currents between states---for instance, from $G_{n+1,p-1}$ into $G_{n,p}$ (successful transition), and from $G_{n+1,p}$ into $G_{n,p}$ (failed transition). These are matched by outflows from $G_{n,p}$ to neighboring states. The third and fourth lines of the master equation below encode this inflow/outflow scheme
$$\begin{aligned}
\frac{d}{dt} G_{n, p}(t) =
&;-\mu,g\left(1 - \frac{g}{K}\right)G_{n,p}(t)
+ \mu,(g-1)\left(1 - \frac{g-1}{K}\right)G_{n-1,p}(t) \
&;-\nu_n,n,G_{n,p}(t)+ \nu_n,(n+1),G_{n+1,p}(t)
- \nu_p,p,G_{n,p}(t) + \nu_p,(p+1),G_{n,p+1}(t) \
&;-\tau\left(\frac{p}{g}\right)\left(1 - C\left(\frac{p}{g}\right)\right)n,G_{n,p}(t) \
&;+ \tau\left(\frac{p-1}{g}\right)\left(1 - C\left(\frac{p-1}{g}\right)\right)(n+1),G_{n+1,p-1}(t) \
&;-\tau\left(\frac{p}{g}\right)C\left(\frac{p}{g}\right)n,G_{n,p}(t)
+\tau\left(\frac{p}{g+1}\right)C\left(\frac{p}{g+1}\right)(n+1),G_{n+1,p}(t) ; .
\end{aligned}$$
Similarly, the first two lines represent a simple population dynamics. The first line represents recruitment, where individuals enter as non-programmers, following logistic growth with a group-level carrying capacity $K$ (downward arrows). The carrying capacity reflects how research groups are limited by varying constraints, such as the time and energy of principal investigators to mentor their students. Here we assume that all groups have the same carrying capacity, but future work could explore how differences in carrying capacity arise based on a number of mechanisms.
The second line captures the system's outflow, as both programmers and non-programmers may graduate or leave at rates $\nu_n$ (upward arrows) and $\nu_p$ (leftward arrows), respectively. Non-programmers may also leave due to a failed attempt to learn programming. While this is a strong assumption, we interpret this exit mechanism as a stylized representation of the broader phenomenon known as the leaky pipeline in academia [@clark_blickenstaff_women_2005; @alper_pipeline_1993], whereby members of underrepresented groups exit at higher rates than those from historically established groups. Given the growing importance of computational skills, such transitions may exacerbate existing inequalities--an effect that has been documented in computer science [@hicks_programmed_2017; @abbate_recoding_2012].
Results
Bimodality and computational hysteresis
We first run the model under a range of conditions to explore the coexistence of computational and non-computational groups. We assume that each group can contain at most 12 programmers and 12 non-programmers. Empirical studies suggest that mid-sized research groups are well approximated by a Poisson distribution with a mean of 10 individuals [@cook_research_2015], from which we specify the groups' carrying capacity of 14 individuals per group. This results in a state space of 114 possible group configurations, each corresponding to a differential equation to integrate. For each run, we use $t=10,000$ timesteps, which we find to be sufficient time for the system to stabilize.
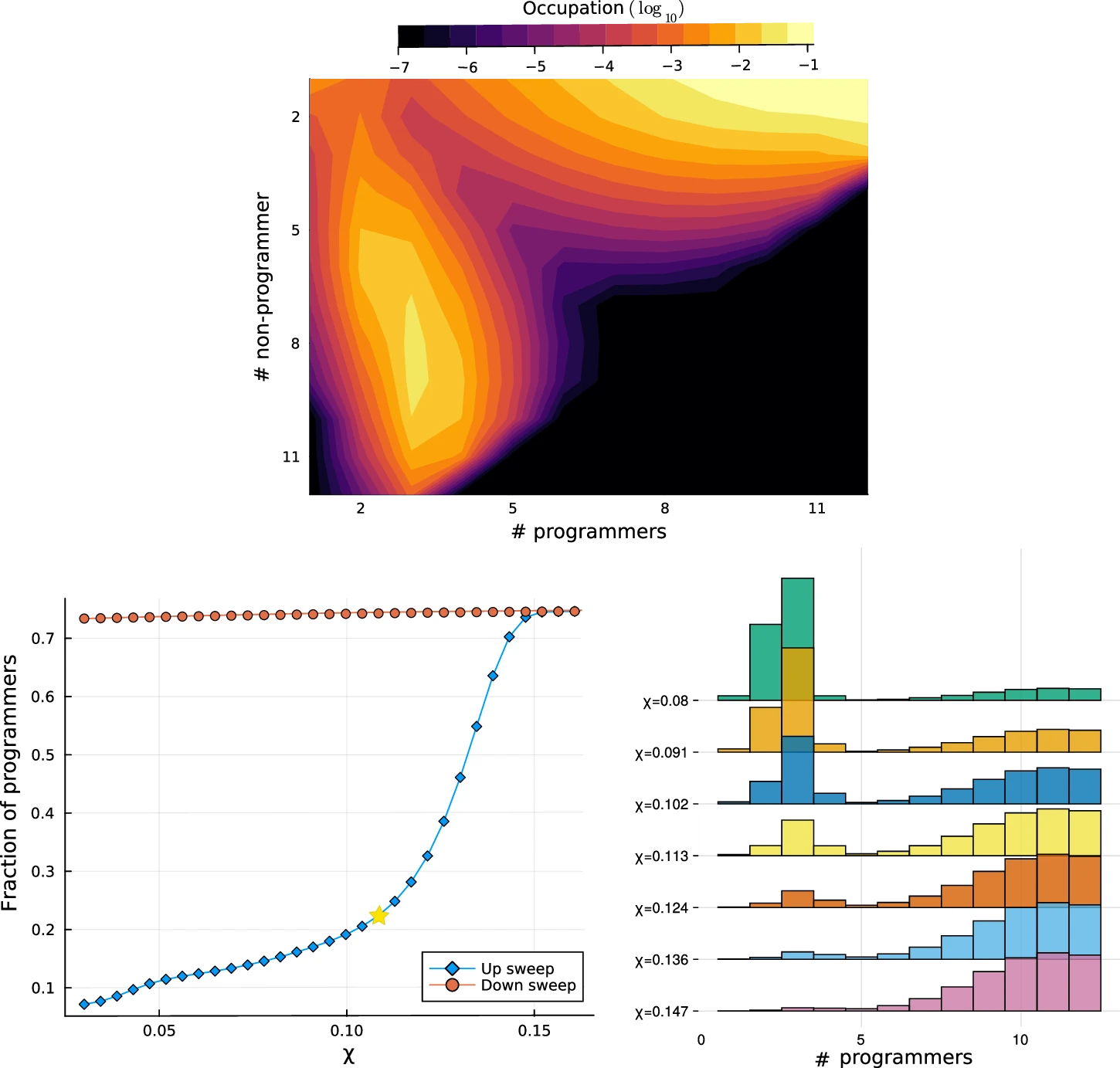
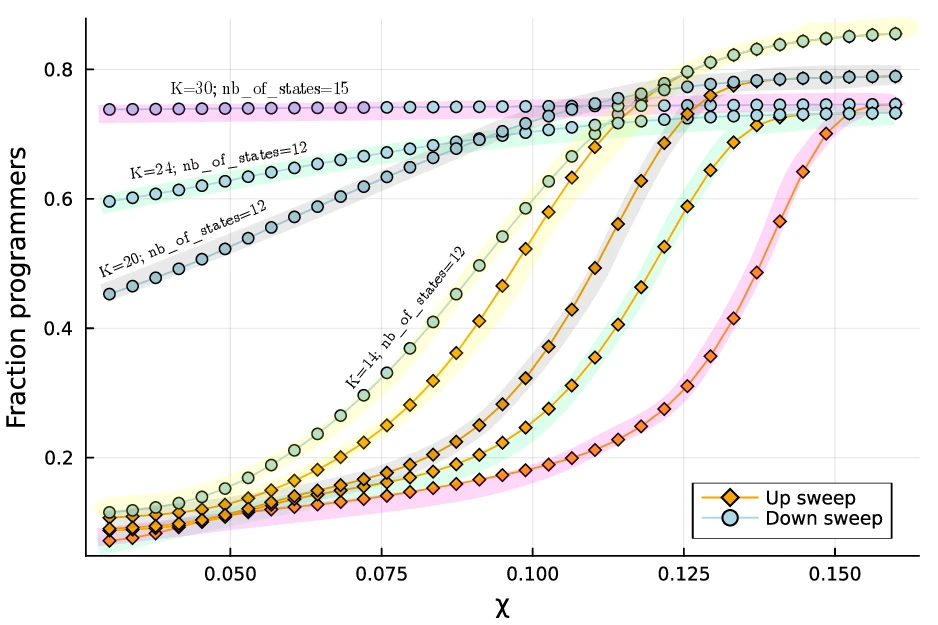
We find that our system exhibits bimodality under specific conditions. In the top panel of Fig. 1.3{reference-type="ref" reference="fig:hysteresis"}, we show one realization of this bimodality. For bimodality to emerge, the benefit cutoff $\chi$ must exceed a certain threshold value. The bottom left panel of Fig. 1.3{reference-type="ref" reference="fig:hysteresis"} shows the resulting hysteresis loop: when the system begins in a programming-poor environment (the "up sweep"), the fraction of programmers remains low until the threshold is crossed (indicated by the star). Beyond this point, the system becomes bimodal. In contrast, when starting with a high proportion of programmers, the system remains in a computational regime even as the benefit cutoff is reduced. The bottom right panel of Fig. 1.3{reference-type="ref" reference="fig:hysteresis"} shows the evolution of the bimodal distribution of groups with programmers changes with respect to benefit cutoff $\chi$. As above the threshold $\chi$, we can see how non-programmer groups are drawn toward the second, more computational regime.
We note that for a fixed maximum group size (24, in the case considered), a lower carrying capacity $K$ tends to weaken the irreversibility of the hysteresis effect. We show in the Appendix values of $K$ at which the down sweep exhibits a partial decrease. We take this result to mean that the strength of hysteresis may depend on group size, which is left for future work.
Fast and slow computational transitions
Given that a computational transition does occur in our system, we seek to answer the following: what strategies do groups adopt in response to that transition? From the group perspective, one strategy is to accelerate the transition; push individuals to learn programming, even though it might be costly to them. However, such a fast transition might come at a cost: it could increase the number of individuals being left behind during the transition. An alternative is to slow down the transition, giving time for individuals to adapt. This might improve the survival rate, even if it takes longer for the full benefits of the transition to be realized.
To explore this trade-off, we consider a system that starts at an equilibrium state where few groups have programmers and finishes in an alternative state with many programmers. We let the system evolve for a fixed number of time steps (sufficiently long for the system to stabilize) under different conditions and measure the "half-time" of the transition. That is, since groups are independent, we measure the expected time for half of the groups to make the transition into the computational regime. To do so, we define the computational regime as the smallest region around the mode of the final state that contains a chosen fraction of the total probability mass (an 80% threshold is used; sensitivity analysis is provided in the Appendix). By tracking how much of the total group population falls inside this region at each time point, we obtain a principled measure of the system's progression toward programming adoption. Additionally, we keep track of the cumulative loss as the total number of individuals who attempted the transition but failed during the transition.
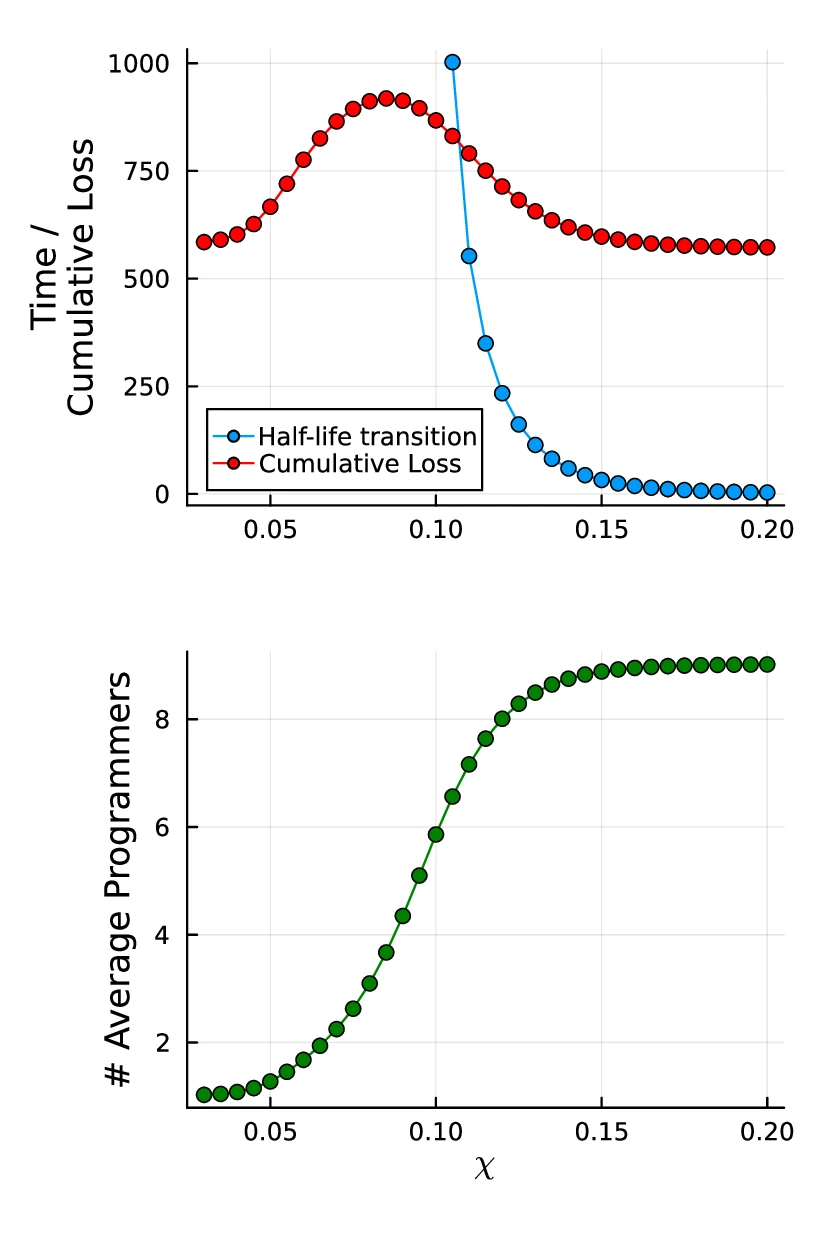
We find that faster half-life transitions are associated with lower cumulative loss (see Fig. 1.4{reference-type="ref" reference="fig:transition"}). Conversely, a slower half-life transition implies that many individuals are left behind. In other words, when the transition takes longer, more individuals are attempting the transition in an unfriendly or high-cost learning environment, leading to higher cumulative loss. We find that the half-life transition time exhibits self-reinforcing behavior above a certain threshold in $\chi$, suggesting the presence of positive feedback effects once a critical point is crossed.
The same qualitative result holds under a wide range of conditions, but the specifics change as we increase and decrease the midpoint and slope of the cost function, as well as the sensitivity of the transition rate ($x_c$, $k_c$, and $k_\tau$, respectively).
Discussion
We developed a group-based model in which the costs and benefits of learning a new skill depend on group composition. Using programming in the humanities as a case study, we show that the model exhibits irreversible hysteresis: once institutional support facilitates the transition to programming, the latter persists even if the support is later withdrawn. By framing learning dynamics and skill acquisition in science as a public goods game imgded in a contagion model, our approach captures the nonlinear influence of group dynamics on individual decision-making.
Focusing on the transition between two alternative stable states, we examine how increasing group-level benefits affects individual outcomes during the shift. In particular, our results show that institutions supporting faster transitions can reduce the number of students left behind--highlighting a trade-off between the rate at which the transition unfolds and cumulative loss. We hope these findings encourage further research, especially as emerging technologies continue to reshape practices across disciplines. More broadly, our results underscore the potential tension between group-level incentives and individual costs, which may or may not be aligned.
While full-scale implementation of group-based learning dynamics remains a long-term goal, we foresee two promising branches of empirical research that could complement and accelerate progress alongside further modeling efforts. First, examining the role of institutional support in fostering self-reinforcing behaviors---not at the level of individuals, but in shaping group norms and practices. By targeting groups rather than individuals, institutions may more effectively catalyze the adoption of new skills through emergent, collectively reinforced norms. Second, a more experimental branch could focus on identifying where and how computational transitions are occurring, in order to strategically allocate resources and support at the community level.
Future work could more explicitly model how formal institutions invest in groups to promote targeted behaviors and how intergroup relationships shape learning dynamics. For example, adaptive hypernetworks [@burgio_adaptive_2023] could capture scenarios where individuals who acquire a skill migrate from programming-poor to programming-rich environments to reduce personal costs. This may lead to counterintuitive outcomes: groups lacking sufficient infrastructure might be worse off after a transition than before, as trained individuals leave---removing both capacity and momentum for local adoption. Focusing solely on individuals risks missing the dual role that both individuals and groups play in the diffusion of innovation.
Code and Data Availability Statement
Code can be found at https://github.com/jstonge/modeling-comp-transition/.
Appendix
Lower carrying capacity weaken hysteresis
We note that in our current results, our main hysteresis plot is sensitive to the system size and carrying capacity. Typically, we find that the hysteresis weakens depending on the combination of the number of states and $K$.
 {#fig:extra-hysteresis
width="80%"}
{#fig:extra-hysteresis
width="80%"}
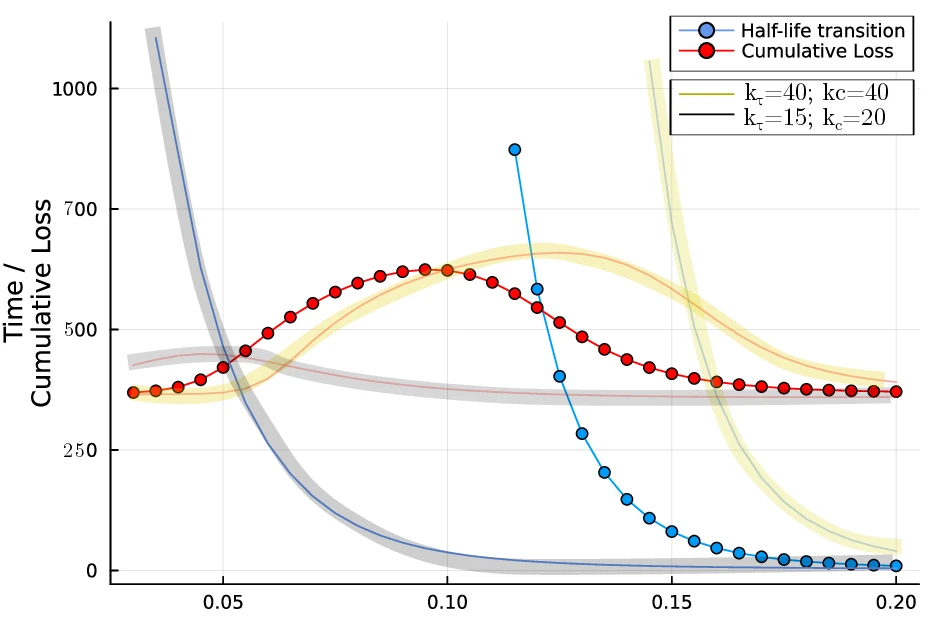
Effects of $k_\tau$ and $k_c$ on transition half-life
While the specific numerical results depend on parameter values, we find that the qualitative behavior remains robust. Increasing the sensitivity to net payoff ($k_\tau$) and the steepness of the cost drop near $x_c$ makes the transition easier overall. However, this also raises the threshold benefit ($\chi$) required to trigger the transition.
Quantifying computational transition?
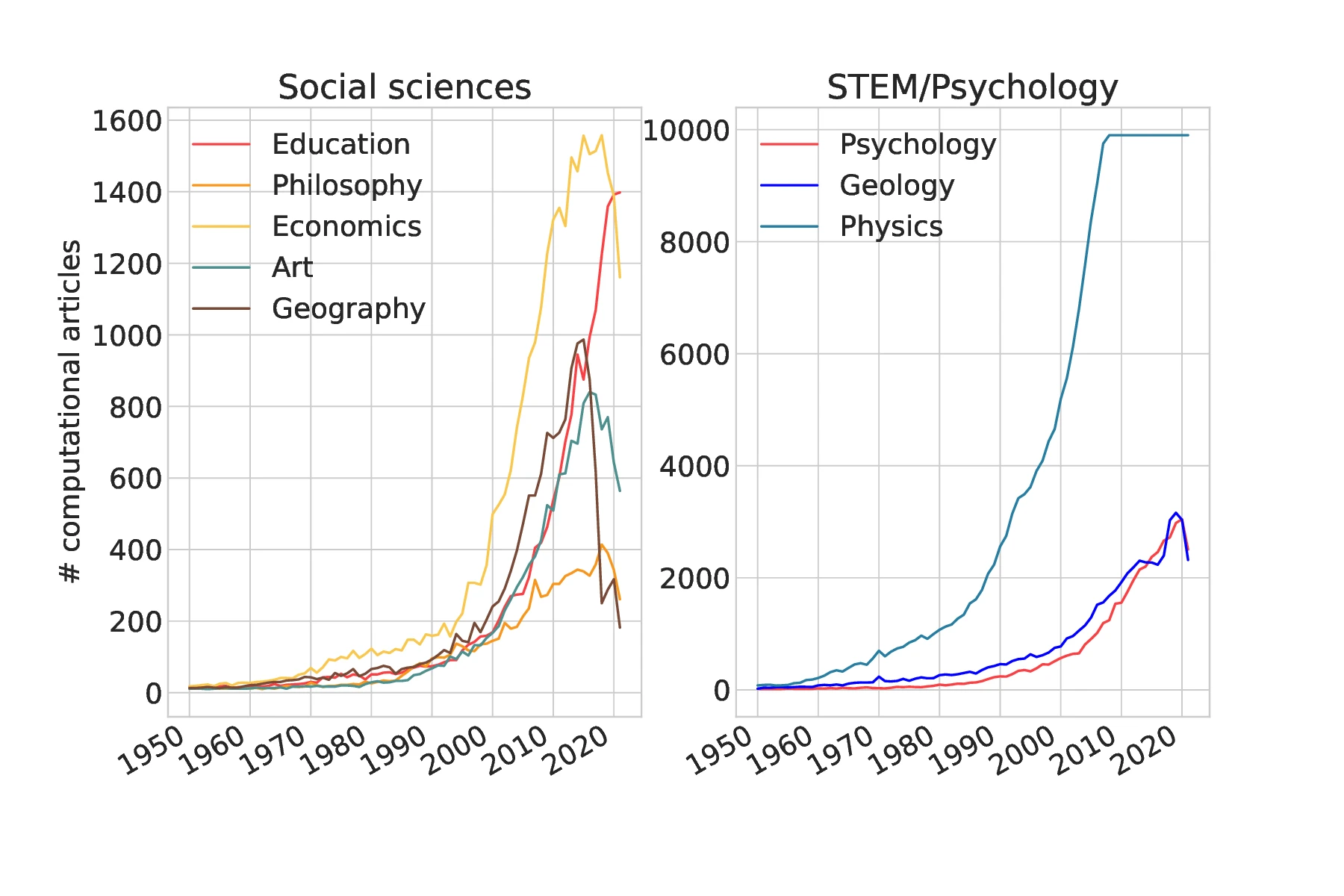
A keyword search in AllenAI's S2ORC database reveals a growing presence of computational approaches and thinking in traditionally qualitative fields (see Fig. 1.1{reference-type="ref" reference="fig:riseprog"}). We use the term "computational" as a proxy for the rise of programming. For example, in disciplines like physics and the social sciences, "computational" often refers to engaging with traditional topics through simulations, observational data, or both.
As expected, physics shows the highest number of computational articles (capped at 10,000 due to API limits). Geology and psychology show a steady upward trend on a smaller scale. Within the social sciences, economics appears to lead in volume. However, this should be interpreted with caution: these counts are not normalized by field size, and the term "computational" varies significantly in usage across domains. For instance, in education, much of the increase reflects work on computational thinking rather than the use of computational methods per se.
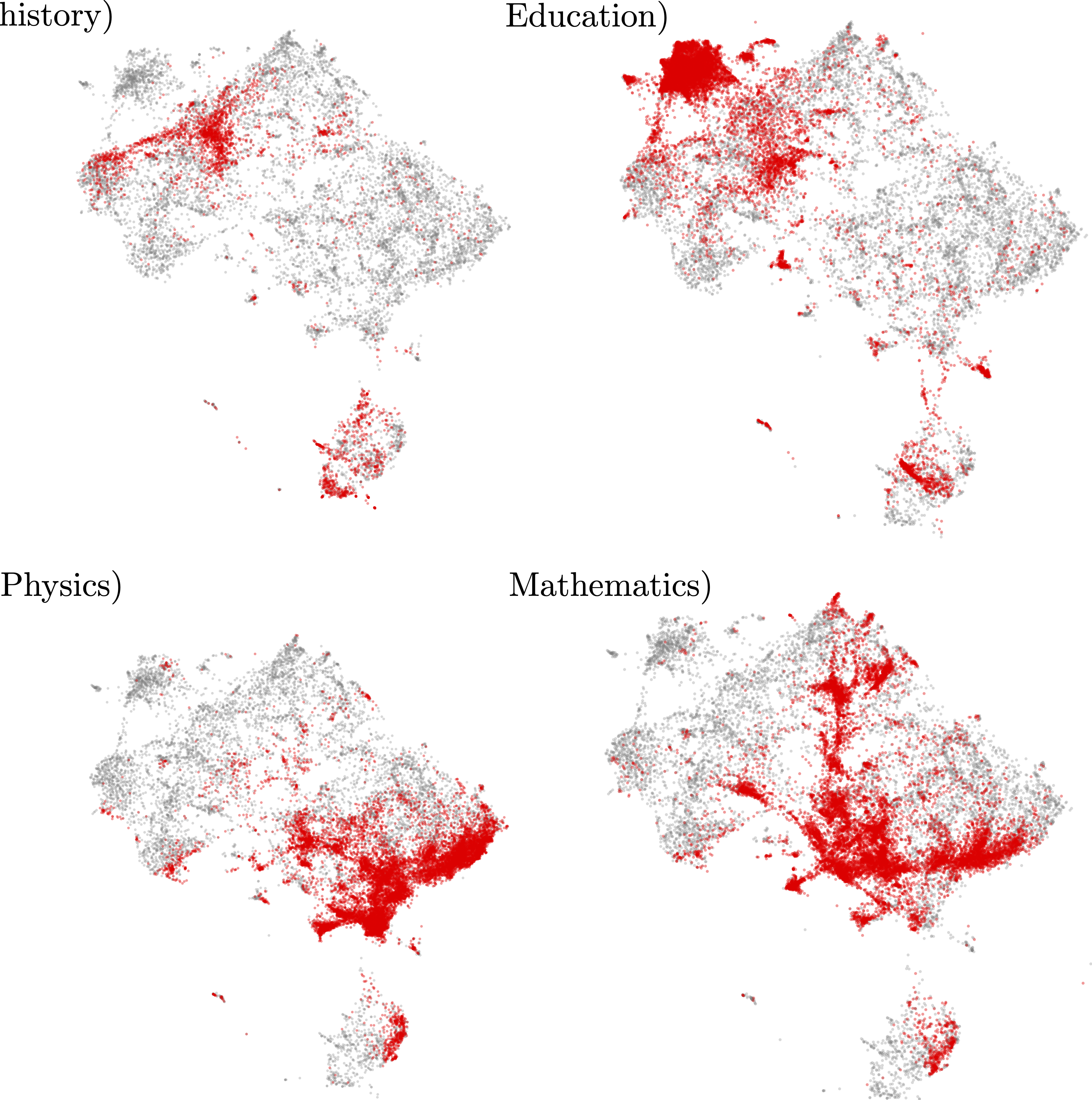
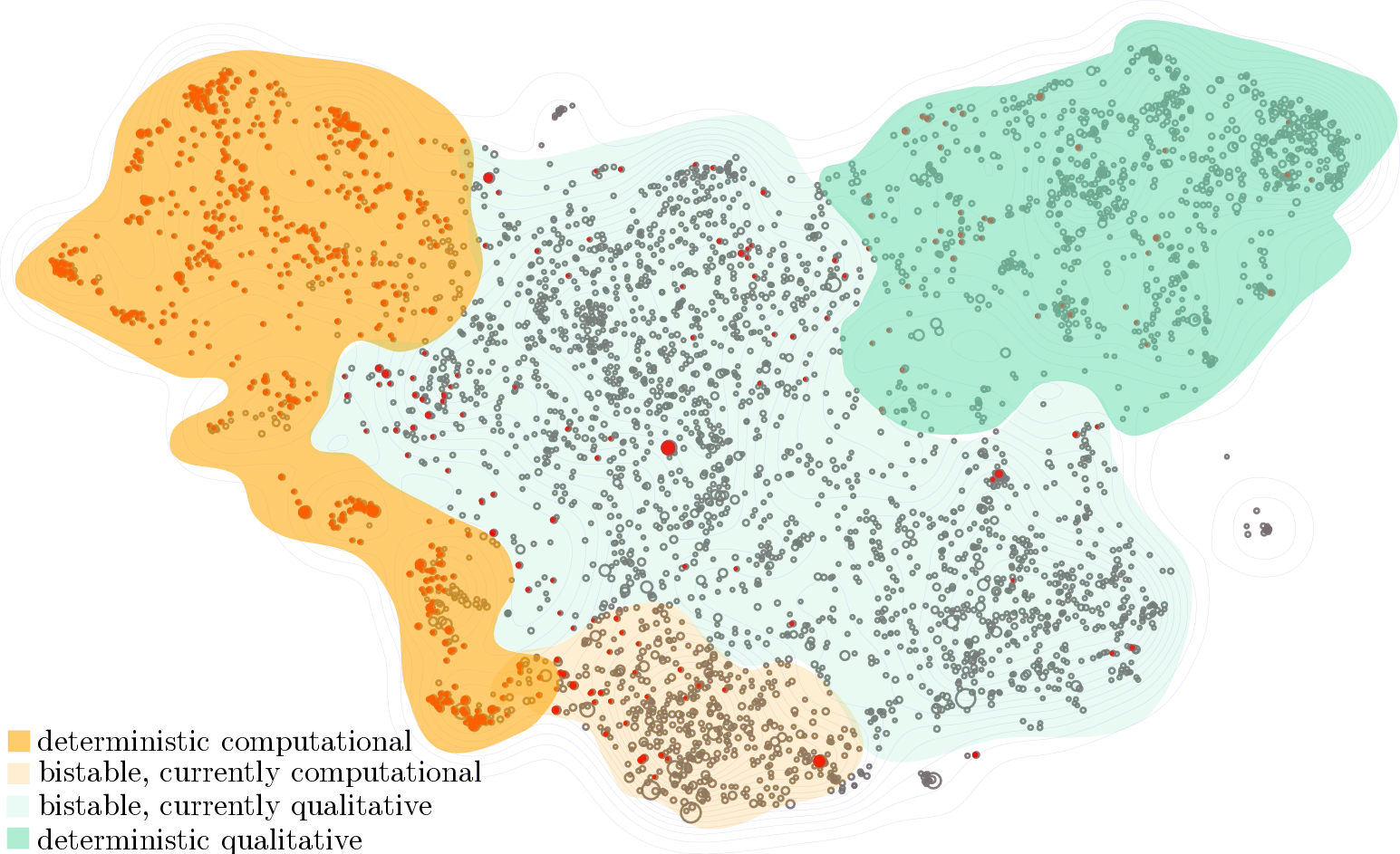
To further clarify meaning, we use an imgding-based visualization (Fig. [1.7]) to show the distribution of semantic similarity among articles labeled as computational, helping to clarify the range of interpretations in our keyword-based analysis.